
elasticsearch
一、简介
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- Apache的开源搜索引擎,提供了搜索引擎的核心API
二、正向索引和倒排索引
- 传统数据库(如MYSQL)采用正向索引,而elasticsearch采用倒排索引
- 什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
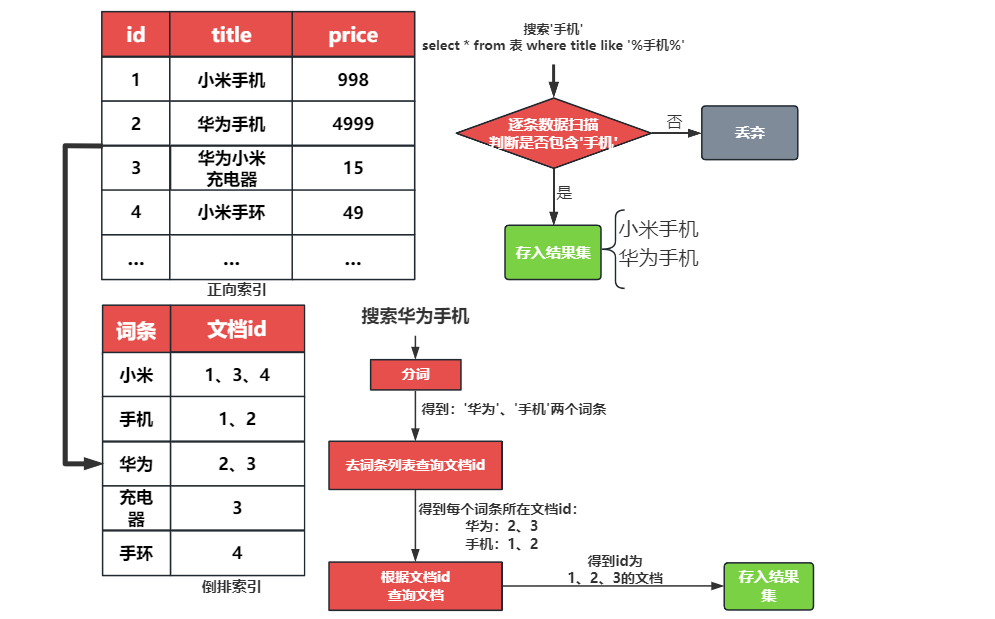
- 什么是正向索引?基于文档id创建索引。查询词条时必须先找到文档,然后判断是否包含词条
- 什么是倒排索引?对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
三、elasticsearch与MySQL的概念对比
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中

索引
- 索引(index):相同类型的文档的集合
- 映射(mapping):索引中文档的字段约束信息,类似表的结构约束
| MYSQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),一条条的数据,类似数据库中的行(Row)文档就是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构 |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CURD |
架构
MYSQL:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
四、部署elasticsearch和kibana
部署基于Docker
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习
4.1、创建网络
首先需要创建一个docker网络用于elasticsearch与kibana互连
1 | docker network create es-net |
4.2、拉取elasticsearch和kibana的镜像
1 | docker pull docker.elastic.co/elasticsearch/elasticsearch:7.12.1 # elasticsearch镜像地址 |
4.3、运行ES
运行docker命令,部署elasticsearch
1 | docker run -d \ |
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
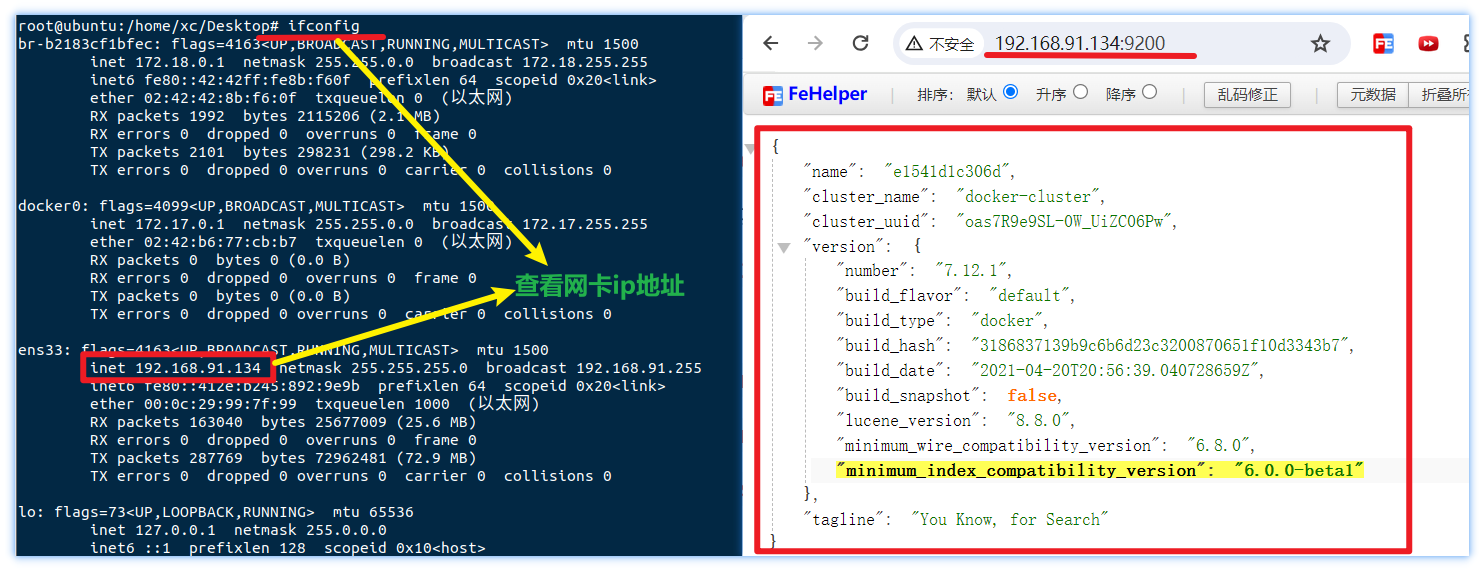
在浏览器中输入:http://192.168.91.134:9200 即可看到elasticsearch的响应结果:
4.4、运行Kibana
运行docker命令,部署kibana
1 | docker run -d \ |
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
1 | docker logs -f kibana |
查看当前运行日志,当看到下述日志说明运行成功
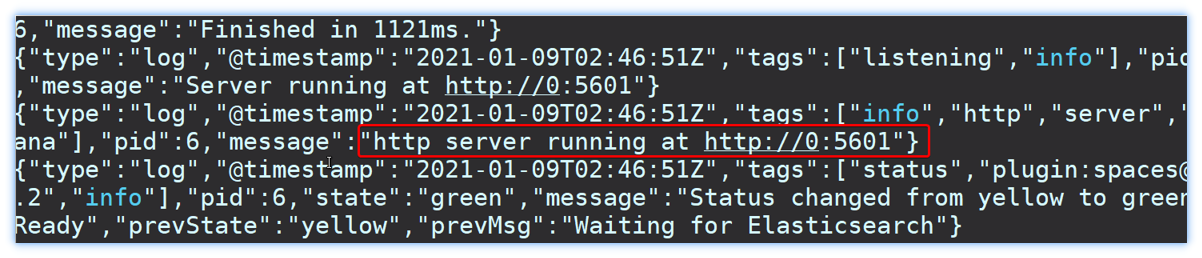
此时,在浏览器输入地址访问:http://192.168.91.134:5601,即可看到结果
4.5、DevTools
kibana中提供了一个DevTools界面:

这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
五、安装IK分词器
5.1、在线安装ik插件
1 | 进入容器内部 |
5.2、扩展词词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。所以词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
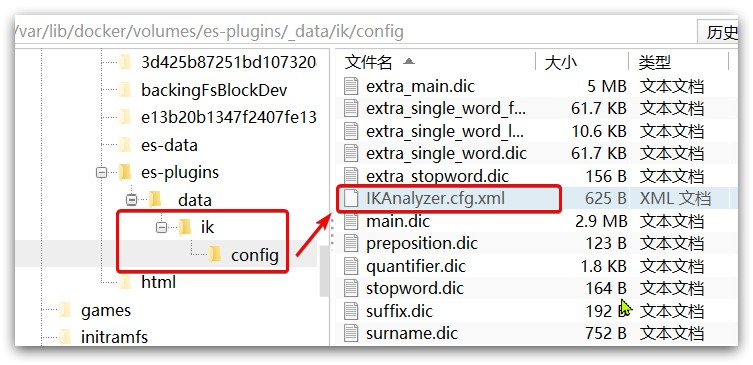
2)在IKAnalyzer.cfg.xml配置文件内容添加:
1 |
|
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
1 | 示例 |
4)重启elasticsearch
1 | docker restart es |
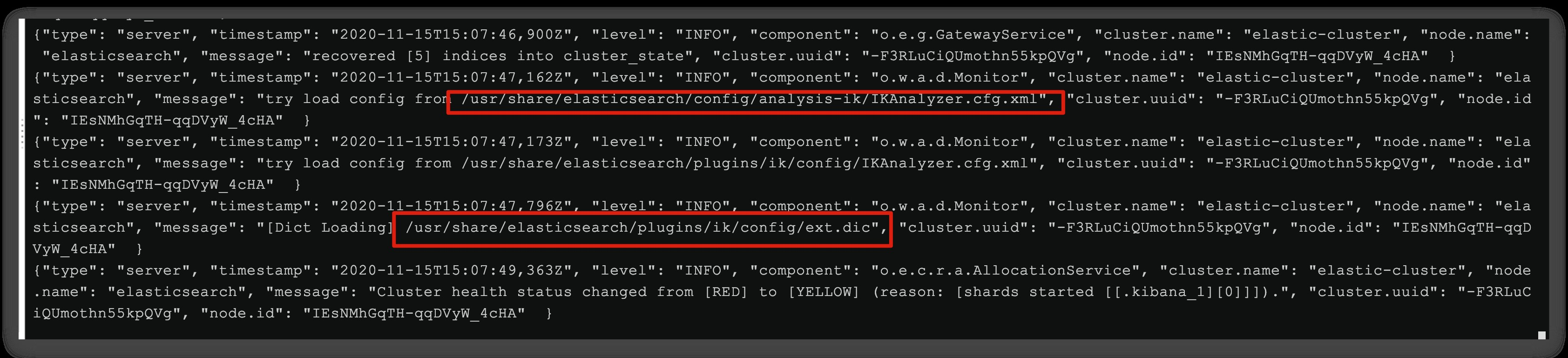
日志中已经成功加载ext.dic配置文件
5)测试效果:
1 | GET /_analyze |
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
5.3、停用词词典
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
1 |
|
3)在 stopword.dic 添加停用词
1 | 沙比 |
4)重启elasticsearch
1 | # 重启服务 |
日志中已经成功加载stopword.dic配置文件
5)测试效果:
1 | GET /_analyze |
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
六、索引库操作
6.1、mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
index:是否创建索引,默认为trueanalyzer:使用哪种分词器properties:该字段的子字段
6.2、创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:
1 | PUT /kucun |
6.3、查看、删除索引库
- 查询索引库语法:
1 | GET /索引库名 |
- 删除索引库语法:
1 | DELETE /索引库名 |
- 修改索引库语法:
索引库和mapping一旦创建无法修改,但是可以添加新的字段
1 | PUT /索引库名/_mapping |
6.4、新增、插叙、删除、修改文档
- 新增文档语法:
1 | POST /索引库名/_doc/文档id |
- 查询文档语法:
1 | GET /索引库名/_doc/文档id |
- 删除文档语法:
1 | DELETE /索引库名/_doc/文档id |
- 修改文档
方式一:全量修改,会删除文档,添加新文档
1 | PUT /索引库名/_doc/文档id |
方式二:增量修改,修改指定字段值
1 | POST /索引库名/_update/文档id |
总结:文档操作
- 创建文档:POST /索引库名/_doc/文档id {JSON文档}
- 查询文档:GET /索引库名/_doc/文档id
- 删除文档:DELETE 索引库名/_doc/文档id
- 修改文档:
- 全量修改:PUT /索引库名/_doc/文档id {JSON文档}
- 增量修改:POST /索引库名/_update/文档id {“doc”:{字段}}
七、RestClient操作索引库
什么是RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
7.1、初始化JavaRestClient
引入es的RestHighLevelClient依赖:
1
2
3
4
5<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
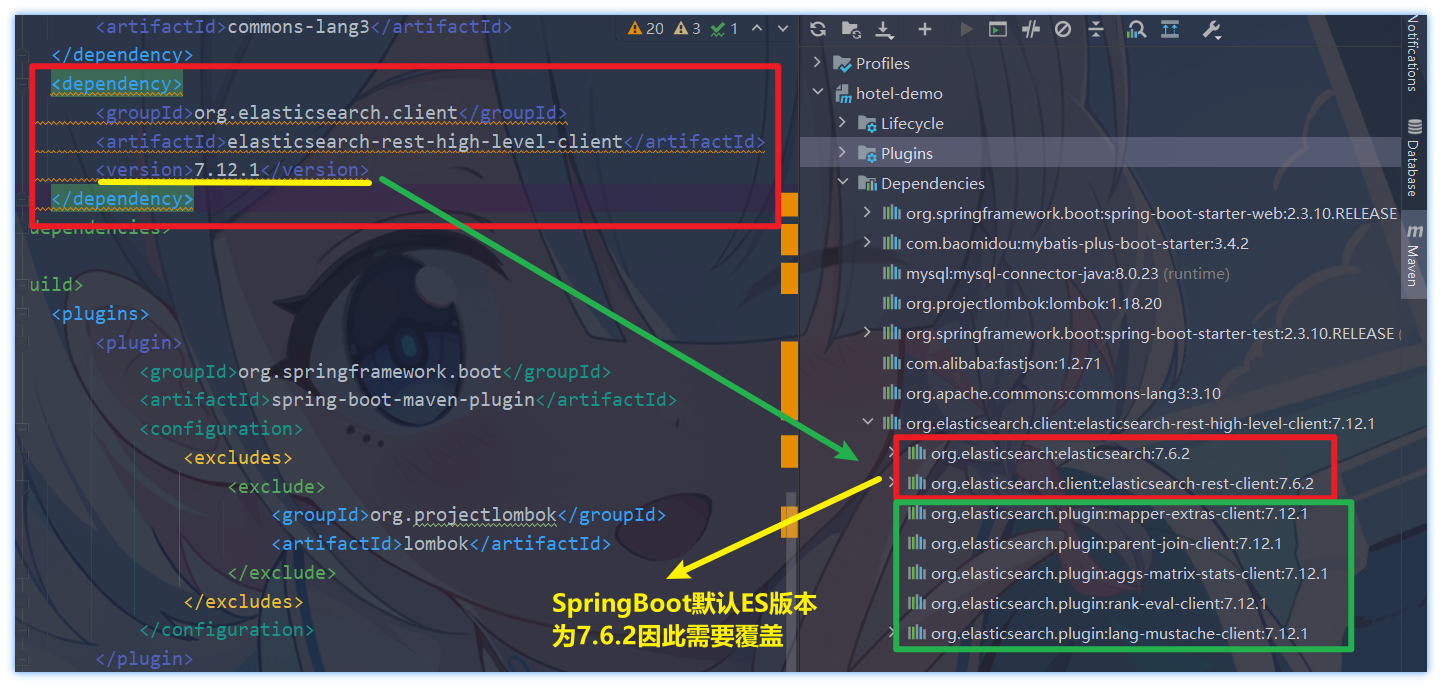
</dependency>导入了依赖我们打开Maven查看一下导入的ES版本会发现有两项ES是7.6.2版本的

因为SpringBoot的默认ES版本为7.6.2因此需要覆盖默认的ES版本
1
2
3
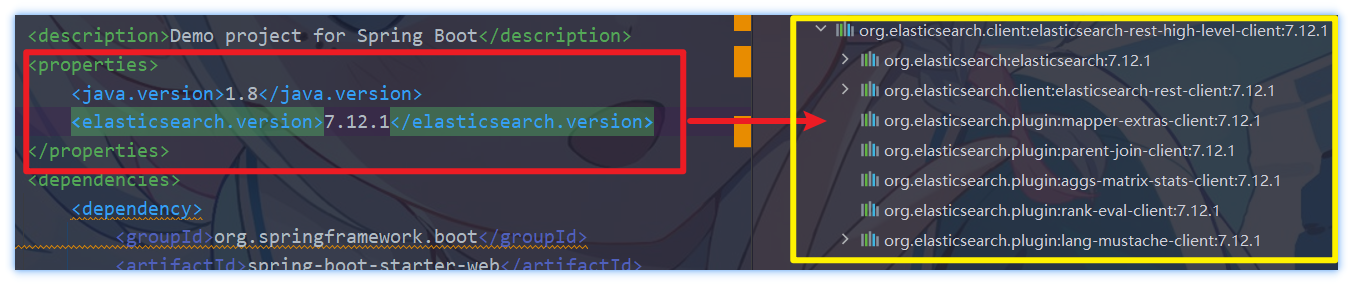
4<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>初始化RestHighLevelClient
1
2
3RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.91.134:9200")
));
7.2、创建索引库
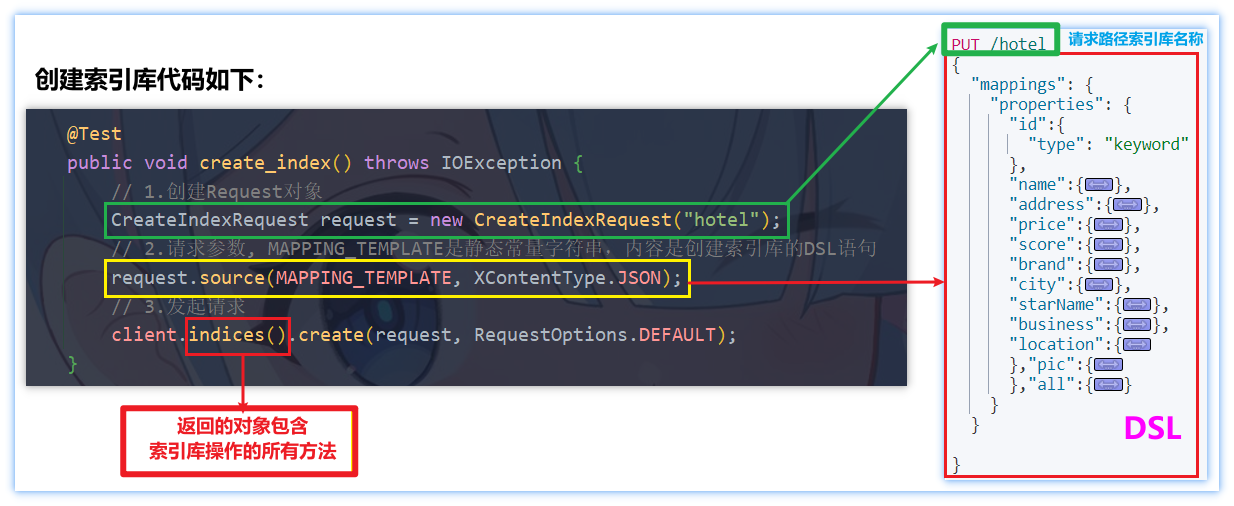
- 创建索引库代码示例
1 | public void create_index() throws IOException { |
7.3、删除、判断索引库是否存在
- 删除索引库代码示例
1 | public void del_index() throws IOException { |
- 判断索引库是否存在
1 |
|
7.4、新增文档
- 新增文档代码示例
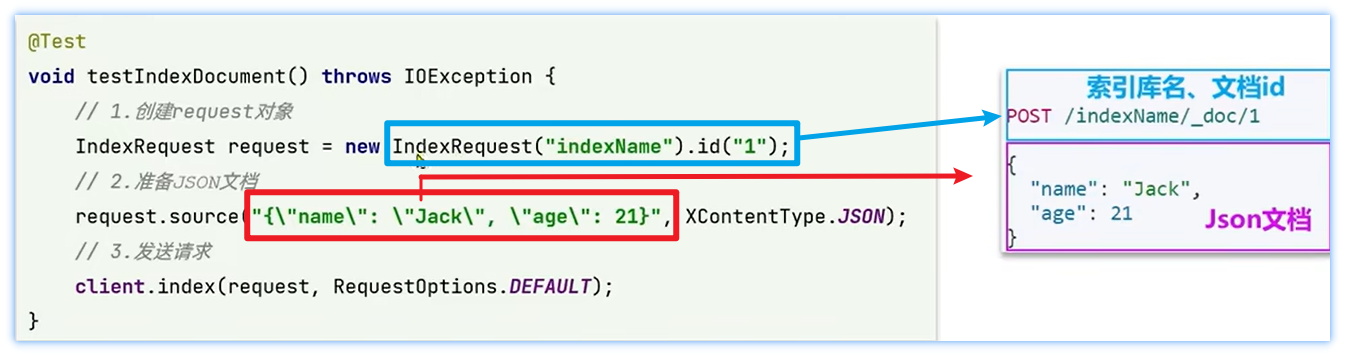
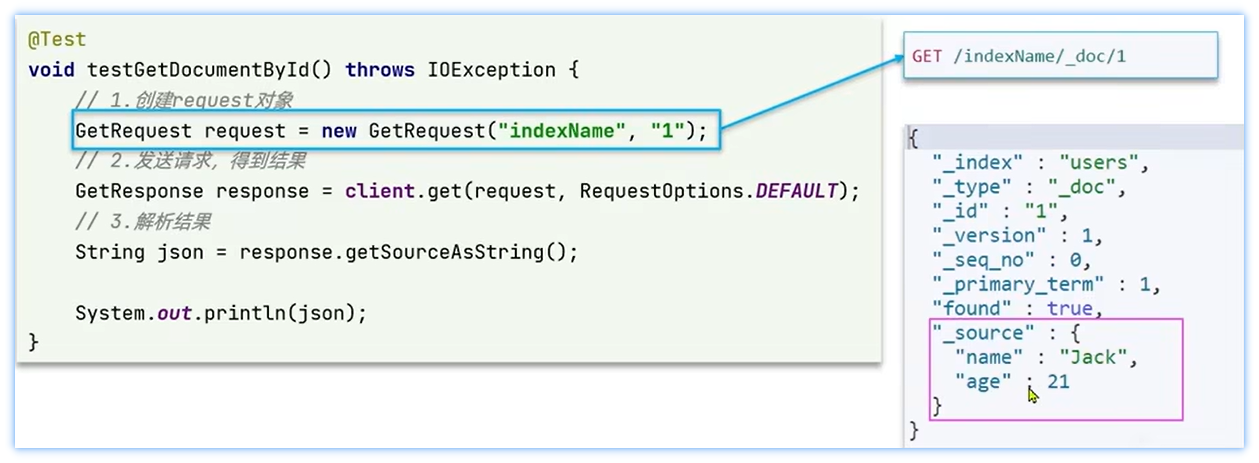
7.5、 查询文档
- 查询文档代码示例
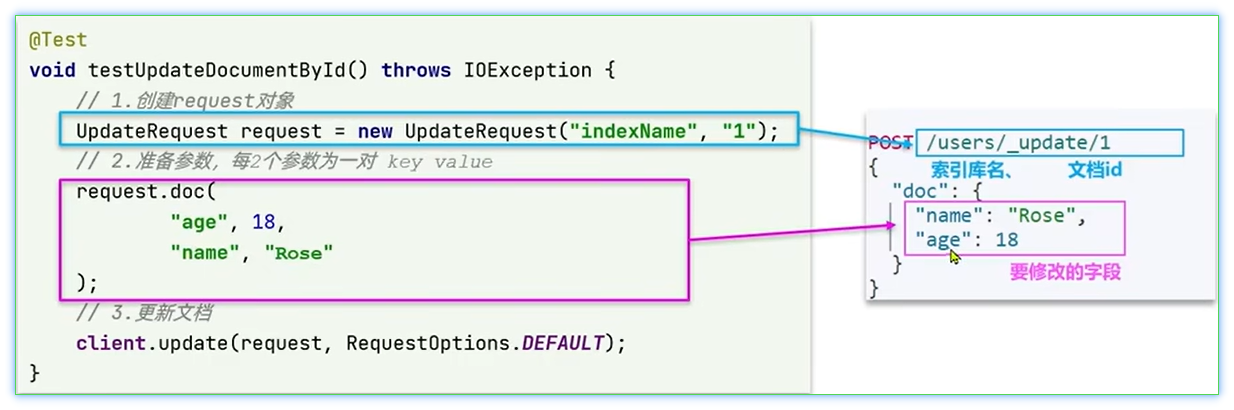
7.6、修改文档
修改文档数据有两种方式:
方式一:全量更新。再次写入一个id一样的文档,就会删除旧文档,创建新文档
方式二:局部更新。只更新部分字段
7.7、删除文档
- 删除文档代码示例
1 | public void deleteDoc() throws IOException { |
文档操作的基本步骤
- 初始化
RestHighLevelClient - 创建 ___Request。___是Index、Get、Update、Delete
- 准备参数(Index和Update时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete
- 解析结果(Get时需要)
7.8、批量添加文档
- 代码示例
1 | public void addAllDoc() throws IOException { |
- 标题: elasticsearch
- 作者: 忘记中二的少年
- 创建于 : 2023-10-25 12:56:00
- 更新于 : 2023-10-25 13:16:39
- 链接: https://github.com/HandsomeXianc/HandsomeXianc.github.io/2023/10/25/ES/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。